Продолжаем цикл статей по совместному докладу Алены Генераловой и Александра Симонова на INFOSTART TECH EVENT 2025 о нагрузочном тестировании (НТ) на 30 000 АРМ на машине баз данных Tantor XData. В первой части рассказали, как ускорить подготовку теста и настроить шаблон для 180 виртуальных машин (ВМ) с помощью Ansible. Во втором материале рассмотрели запуск теста и сбор артефактов, поговорили про архитектуру кластера 1С и настройку свойств СУБД. В этой статье поделимся, с какими проблемами профилирования столкнулись и как удалось их преодолеть.
 Так как мы с коллегами никогда не запускали тестирование сразу на 30 тысяч пользователей, то решили стартовать с 20 000, а с возможными проблемами разбираться по мере их возникновения. Полный прогон теста на 20 тысяч пользователей занял порядка 14 часов. Работа выполнялась в три этапа: подготовка к запуску (1 час), запуск и инициализация пользователей (2 часа) и, наконец, сам тест, который длился 11 часов.
Так как мы с коллегами никогда не запускали тестирование сразу на 30 тысяч пользователей, то решили стартовать с 20 000, а с возможными проблемами разбираться по мере их возникновения. Полный прогон теста на 20 тысяч пользователей занял порядка 14 часов. Работа выполнялась в три этапа: подготовка к запуску (1 час), запуск и инициализация пользователей (2 часа) и, наконец, сам тест, который длился 11 часов.
Дебютный запуск прошел успешно: система работала стабильно и без ошибок на протяжении всего времени. Получив отчет APDEX по результатам теста, мы подумали – хм, как все просто! Однако на следующем тесте на 25 тысяч у нас начались проблемы – сервер СУБД уходил в себя примерно через 40 минут после начала нагрузки. Перезапускали тест на 25 тысяч несколько раз, но проблема стабильно повторялась.
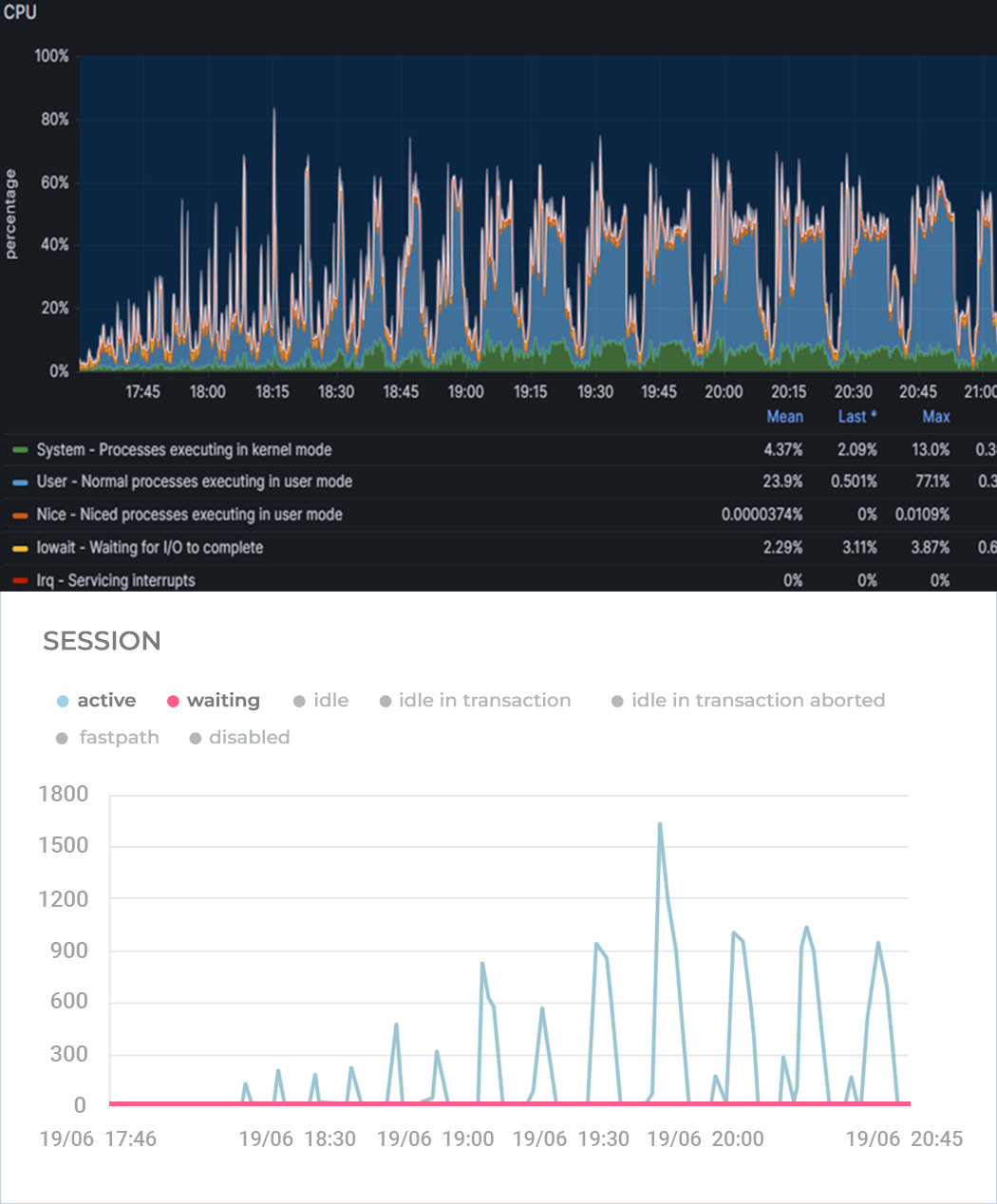
На графиках можно увидеть, как это было: процессор не уходил в утилизацию на 100%, но количество активных сессий на СУБД резко росло до нескольких тысяч пока не упиралось в max_connections. Обработка запросов стала занимать секунды вместо миллисекунд – конечно, с таким поведением тест успешно не завершишь.
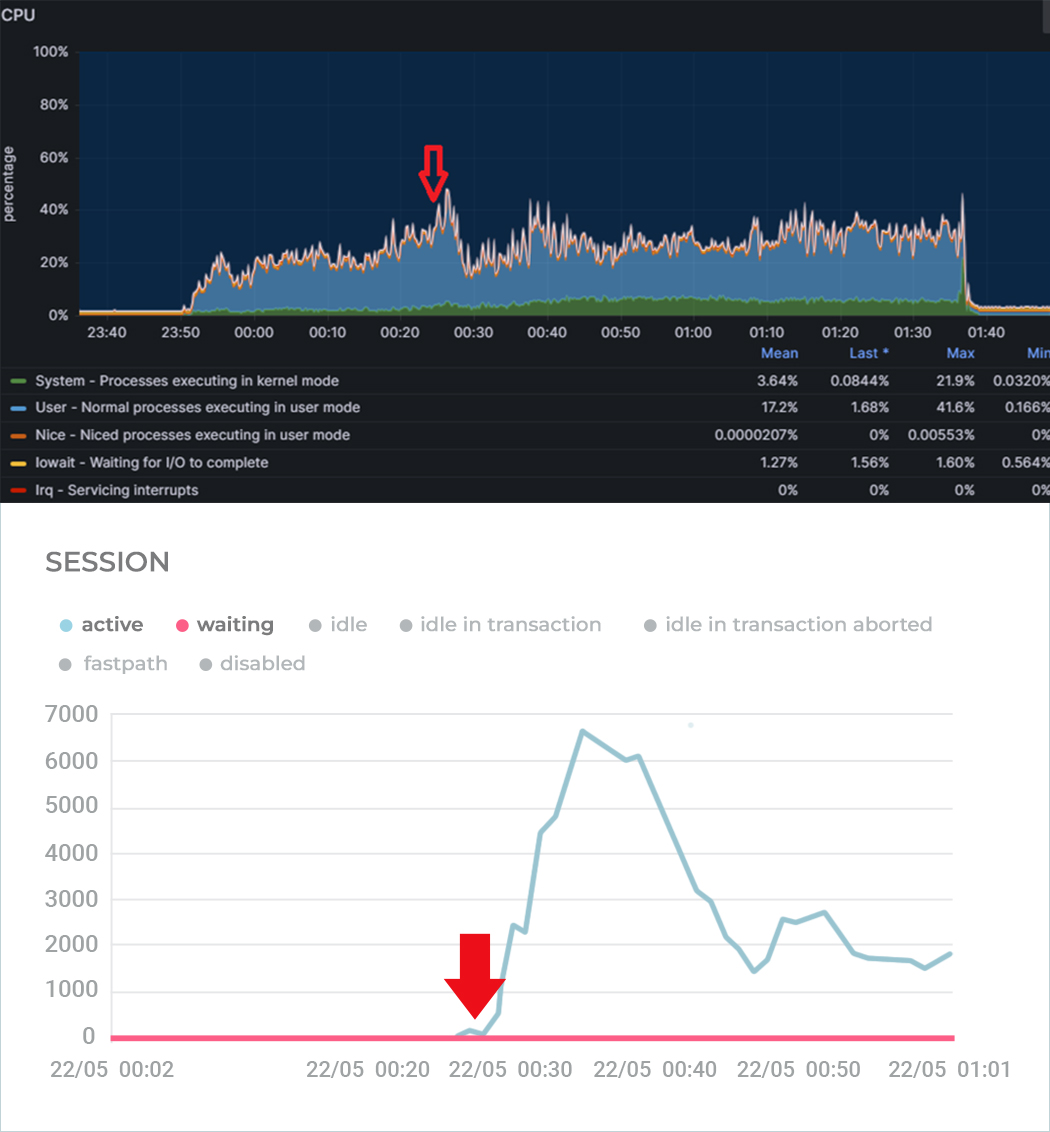
Давайте чуть углубимся в проблему. На видео ниже показан результат вывода простого скрипта к pg_stat_activity, с помощью которого можно без установки дополнительных расширений диагностировать некоторые проблемы при больших нагрузках
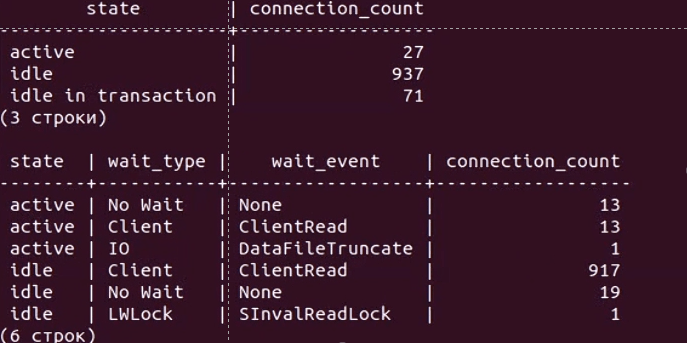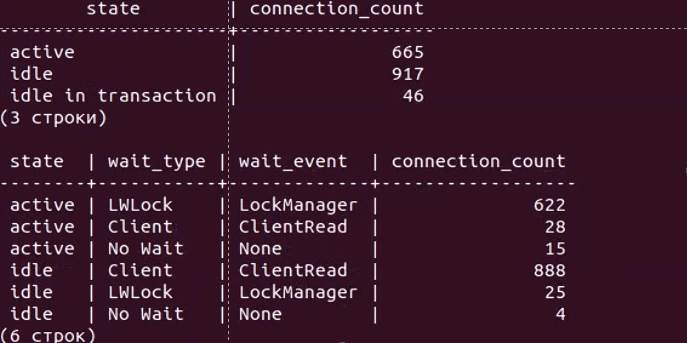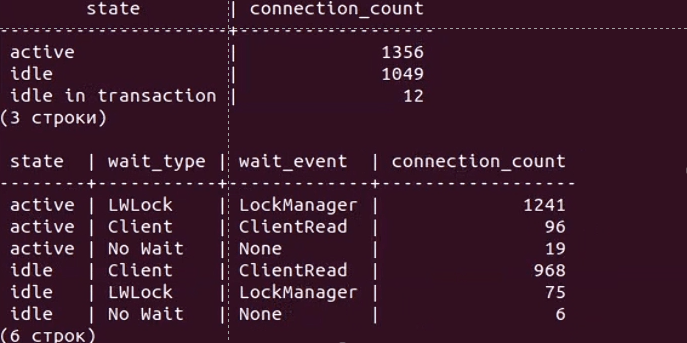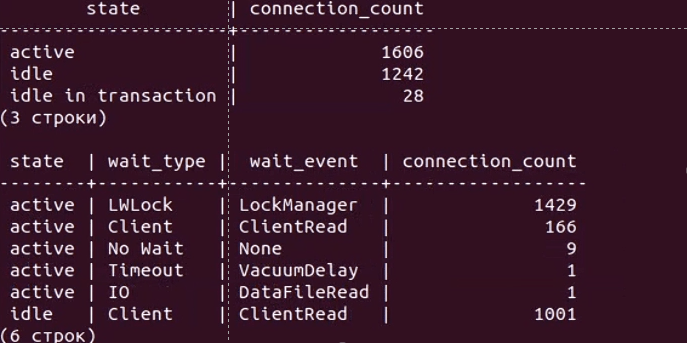
Верхняя таблица отображает количество соединений в разрезе состояний (active, idle, idle in transaction), а нижняя – дополнительно в разрезе типа и события ожиданий. Сначала мы видим, что у нас около тысячи соединений, большая часть из которых находится в режиме ожидания команды (idle). И вдруг количество активных соединений начинает резко расти с 30 до 1000, 2000 и т.д. А сами сессии имеют тип ожидания LWLock с именем события LockManager, т.н. легковесные блокировки (lightweight locks), используемые Tantor Postgres для синхронизации доступа к разделяемым структурам данных в памяти.
Впрочем, эта информация лишь указывала направление для дальнейшего поиска, но не объясняла причины проблем. Чтобы добраться до сути, мы решили проанализировать исходный код и задействовали для этого perf – инструмент профилирования, который показывает, в каких именно функциях Tantor Postgres происходят задержки и где образуются узкие места. Так нам удалось обнаружить первую проблему, связанную с механизмом инвалидационных сообщений.
В Tantor Postgres есть общая очередь сообщений, которая нужна для того, чтобы бэкенды (сеансы) могли обмениваться между собой важной информацией. Под важной информацией понимаются различные DDL-команды, т.е. команды, которые изменяют метаданные таблиц. Давайте рассмотрим, как работает этот механизм:
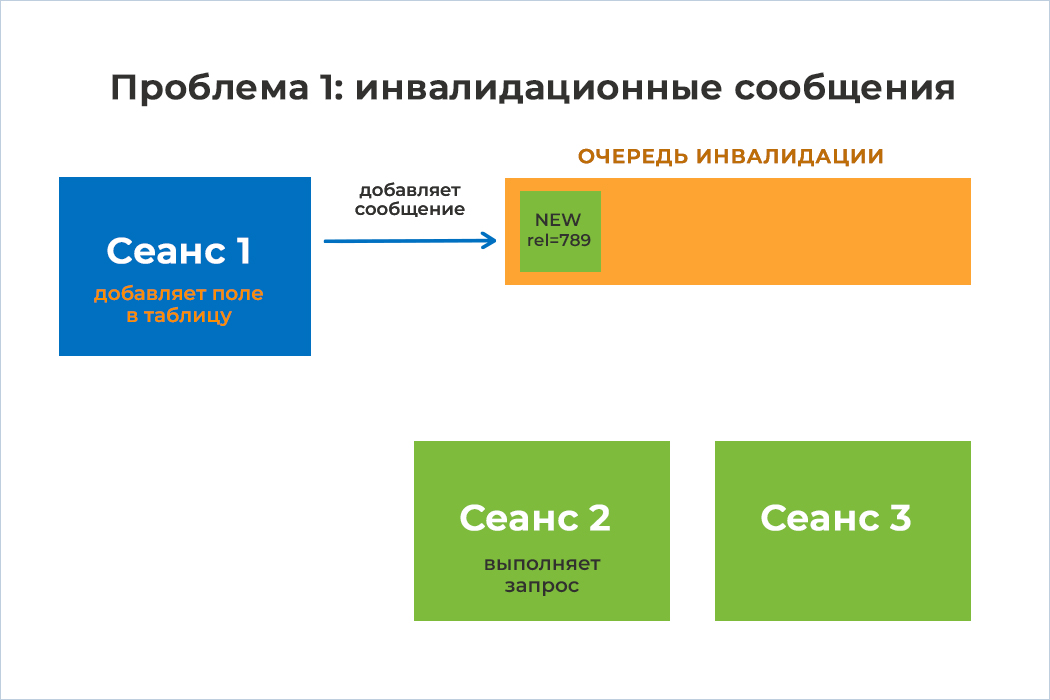
1) У нас есть 3 сеанса на стороне СУБД, которые начинают свою работу. При начале работы они считывают метаданные таблиц из системного каталога себе в локальный кэш, чтобы понимать какие таблицы/индексы есть в базе данных и с чем они могут работать при выполнении запросов
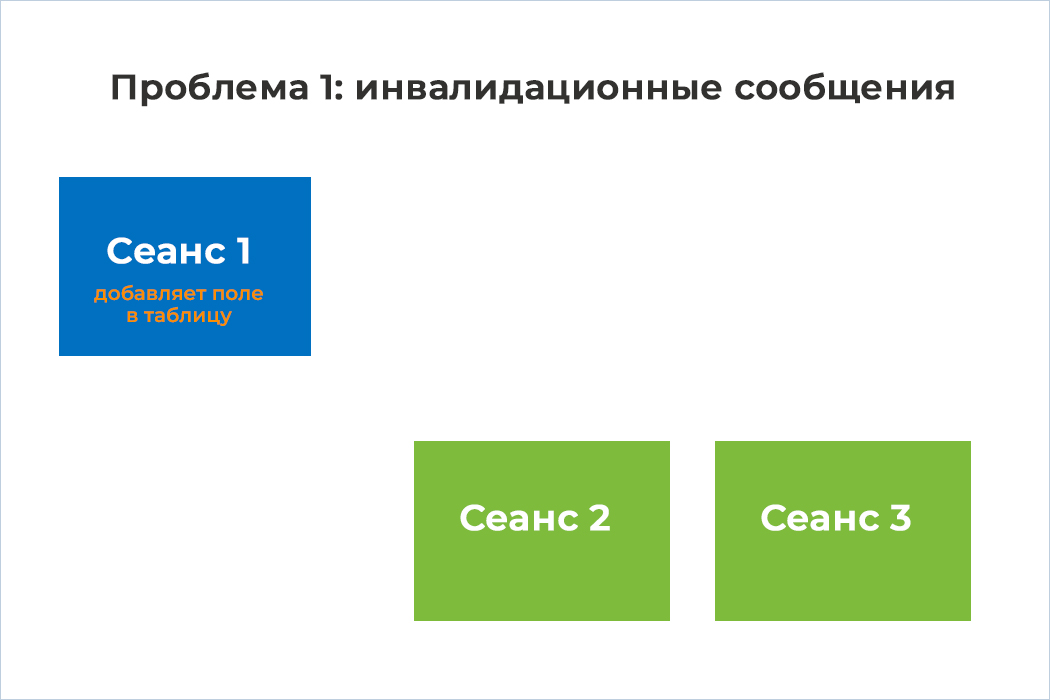
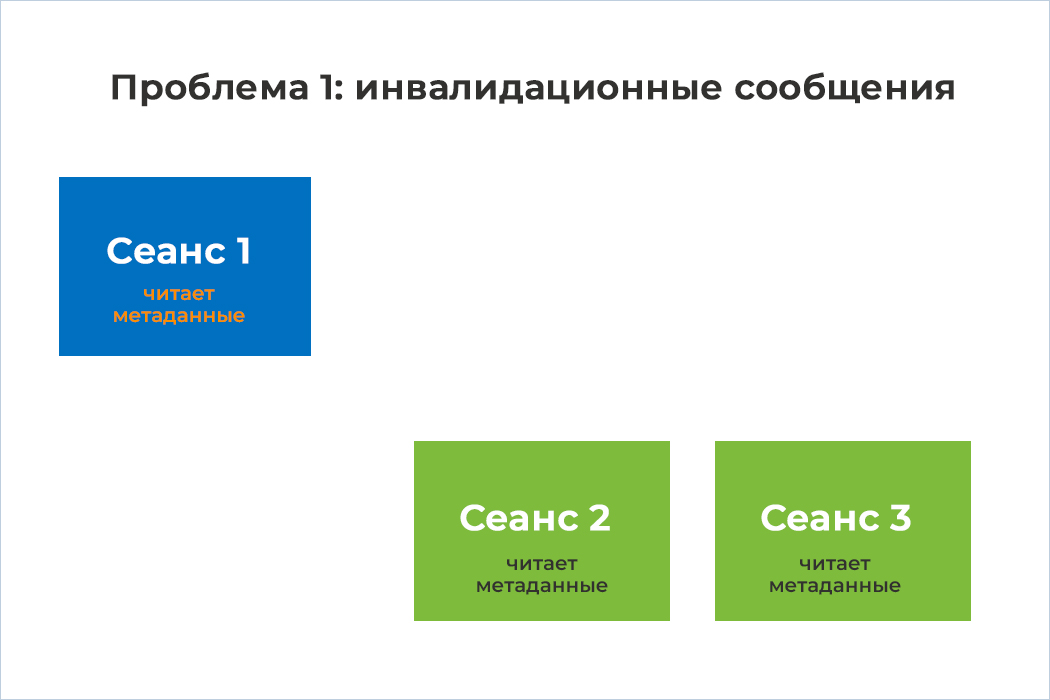 2) В рамках сеанса 1 происходит изменение метаданных таблицы путем добавления в нее нового поля
2) В рамках сеанса 1 происходит изменение метаданных таблицы путем добавления в нее нового поля
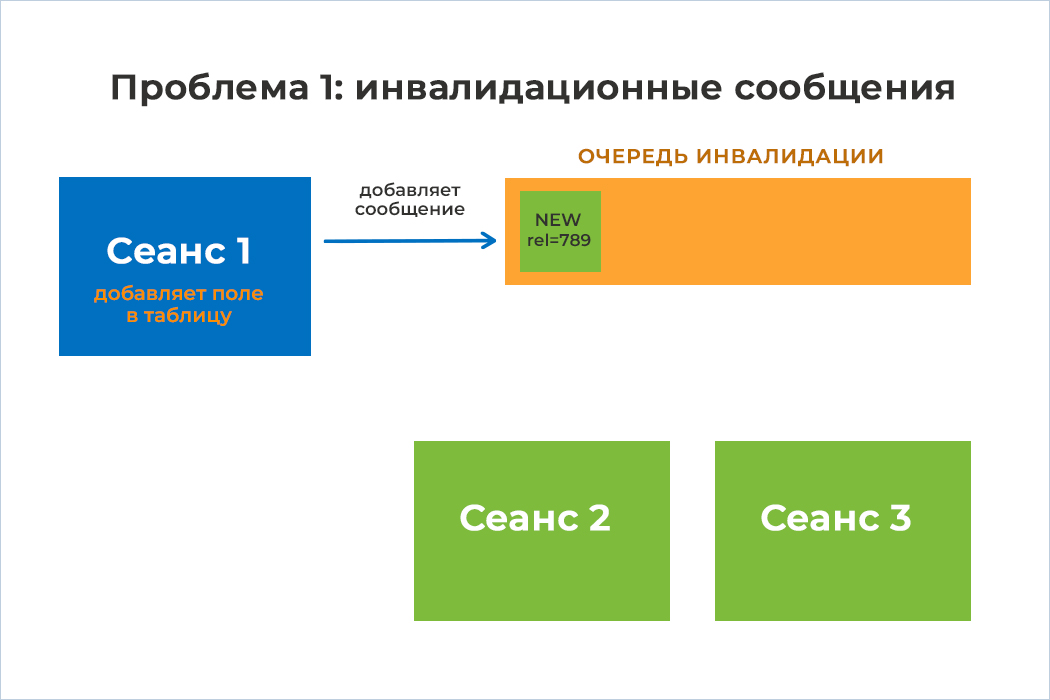
 3) Сеансы 2 и 3 пока не знают, что в какую-то таблицу было добавлено новое поле. Чтобы уведомить их об изменении метаданных, существует очередь инвалидации. После добавления нового поля Сеанс 1 помещает в эту очередь сообщение об изменении метаданных соответствующей таблицы
3) Сеансы 2 и 3 пока не знают, что в какую-то таблицу было добавлено новое поле. Чтобы уведомить их об изменении метаданных, существует очередь инвалидации. После добавления нового поля Сеанс 1 помещает в эту очередь сообщение об изменении метаданных соответствующей таблицы
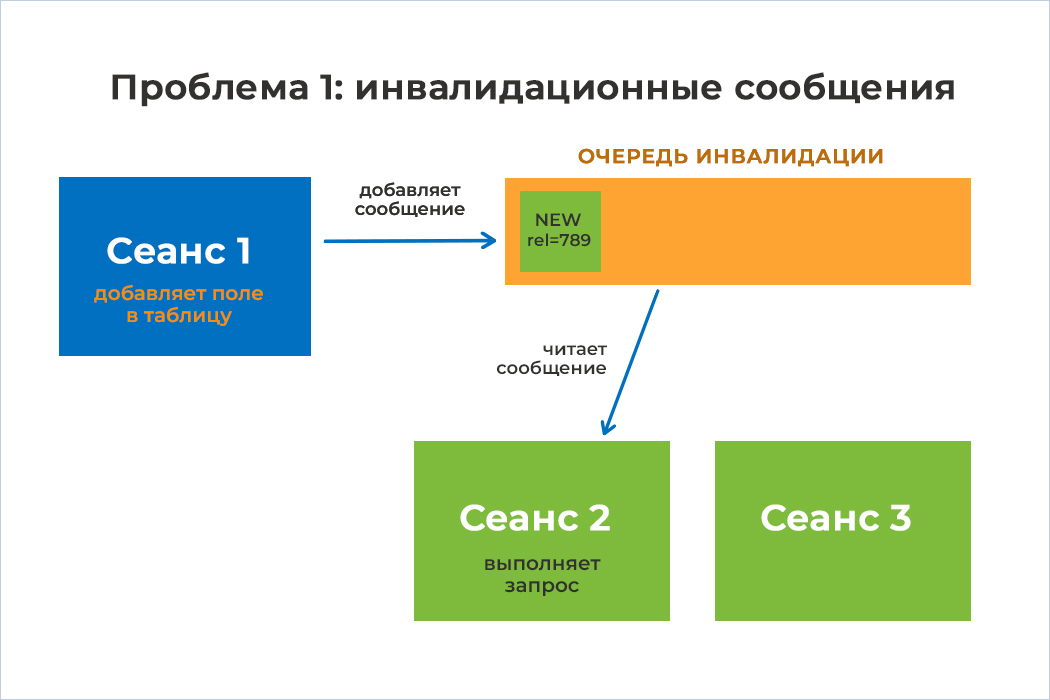
 4) Сеанс 2 выполняет запрос к базе данных, затрагивающий таблицу, в которую Сеанс 1 ранее добавил новое поле. Однако Сеанс 2 пока не осведомлен об этом изменении структуры
4) Сеанс 2 выполняет запрос к базе данных, затрагивающий таблицу, в которую Сеанс 1 ранее добавил новое поле. Однако Сеанс 2 пока не осведомлен об этом изменении структуры
 5) Сеанс 2 обращается к очереди инвалидации с запросом по списку используемых таблиц. В ответ он получает сообщение о добавлении нового поля в одну из таблиц и обновляет эту информацию в своем локальном кэше. Теперь, имея актуальные метаданные, он может выполнить запрос к базе данных без риска получить ошибку об отсутствующей колонке
5) Сеанс 2 обращается к очереди инвалидации с запросом по списку используемых таблиц. В ответ он получает сообщение о добавлении нового поля в одну из таблиц и обновляет эту информацию в своем локальном кэше. Теперь, имея актуальные метаданные, он может выполнить запрос к базе данных без риска получить ошибку об отсутствующей колонке
 Хорошо, но причем тут наш тест, ведь во время работы 30 тысяч пользователей никто не будет менять метаданные таблиц? Однако, 1С постоянно создает временные таблицы и индексы к ним, а это тоже есть изменение метаданных:
Хорошо, но причем тут наш тест, ведь во время работы 30 тысяч пользователей никто не будет менять метаданные таблиц? Однако, 1С постоянно создает временные таблицы и индексы к ним, а это тоже есть изменение метаданных:
- Большое количество сеансов создают временные таблицы и отправляют информацию об этом в очередь инвалидации. Данная очередь имеет ограничение и может хранить только 16384 сообщений
- 2. Когда место в очереди подходит к концу, Tantor Postgres начинает массовую инвалидацию сообщений. Это значит, что все сеансы массово очищают свои локальные кэши метаданных, чтобы чтобы затем загрузить в них актуальную информацию. После очистки каждый сеанс обращается к очереди инвалидации, чтобы подтвердить, что он «догнал» очередь. При этом, каждое такое взаимодействие с очередью инвалидации требует наложения блокировок LWLock, что и является причиной нашей первой проблемы.
Но так как временная таблица существует только в рамках сеанса, который ее создал, и другим сеансам она не нужна, то здесь решение простое: не отправлять в очередь инвалидации сообщения, связанные с временными таблицами.
Разобравшись с причиной, команда «Тантор лабс» доработала Tantor Postgres, после чего мы снова запустили тест, но уже сразу на 30 тысяч пользователей. Тест завершился условно-успешно – получили APDEX 0.635. При этом графики нагрузки по CPU и активным сессиям на СУБД показывали резкие всплески роста активных сессий, которые по-прежнему были следствием LWLock'ов. Да, их стало меньше, но они все же были.
Во время этого прогона мы выполнили еще одно профилирование, которое показало нам следующую проблему, связанную с долгим удалением индексов временных таблиц.
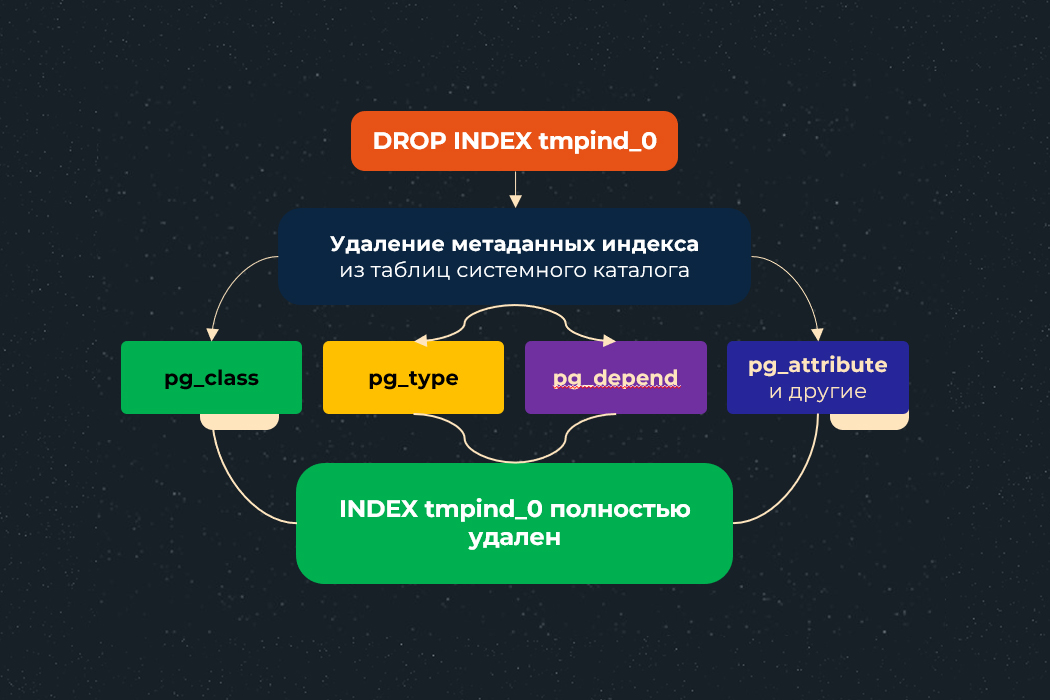
Чтобы удалить индекс, необходимо также очистить из таблиц системного каталога информацию о нем, например:
- pg_class – хранит информацию об идентификаторе индекса
- pg_type – хранит информацию о типах полей, используемых в колонках индекса
- pg_depend – хранит зависимости между объектами БД для операций CASCADE
- pg_attribute – хранит информацию о списке колонок, используемых в индексе и др.
Визуально схему удаления индекса можно представить следующим образом
 Это можно сравнить с физическим удалением ссылки в базе 1С. Допустим, мы удаляем элемент справочника «Номенклатура», и перед тем, как он будет физически удален из базы данных, платформа 1С должна удалить связанные записи из регистров сведений, где измерение имеет тип «Справочник.Номенклатура» и стоит галка «Ведущее». Поэтому операция физического удаления ссылок проходила не так быстро, как нам бы хотелось.
Это можно сравнить с физическим удалением ссылки в базе 1С. Допустим, мы удаляем элемент справочника «Номенклатура», и перед тем, как он будет физически удален из базы данных, платформа 1С должна удалить связанные записи из регистров сведений, где измерение имеет тип «Справочник.Номенклатура» и стоит галка «Ведущее». Поэтому операция физического удаления ссылок проходила не так быстро, как нам бы хотелось.
Аналогично получилось с удалением индекса в Tantor Postgres. Так как при необходимости любой код, включая исходный код данной СУБД, можно оптимизировать, команда «Тантор лабс» именно это и сделала. После этого мы запустили нагрузочный тест на 30 тысяч пользователей и получили APDEX 0.849. Но, несмотря на заметный прогресс, результаты все еще не отвечали нашим требованиям. Поэтому коллеги из «Тантор лабс» еще раз доработали СУБД Tantor Postgres, скорректировав его настройки на основе опыта предыдущих запусков.
Оптимизация дизъюнктивных подзапросов
Во время теста следующий запрос выполнялся около 8000 раз с длительностью 4-15 секунд в зависимости от таблицы, к которой он обращался
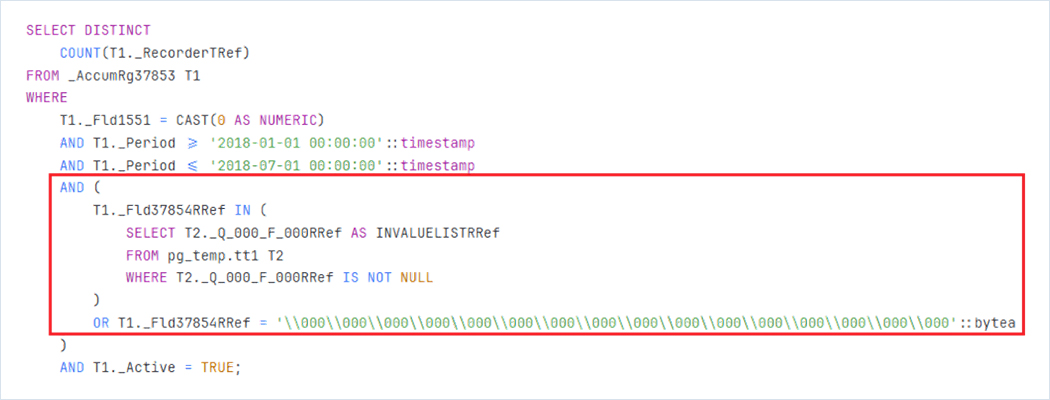 Из текста запроса видно, что по одному полю накладывается отбор через условие OR. При этом индекс по этому полю есть, почему же он не используется? Наличие подзапроса является блокирующим фактором. Планировщик мог бы использовать индекс, если бы на месте подзапроса было простое условие с ИЛИ, сравнивающее колонку с набором констант – в этом случае его можно было бы преобразовать в конструкцию ANY. Однако с подзапросом такое преобразование невозможно, так как пришлось бы сканировать индекс целиком. Поэтому остановились на последовательном сканировании, так как это намного дешевле
Из текста запроса видно, что по одному полю накладывается отбор через условие OR. При этом индекс по этому полю есть, почему же он не используется? Наличие подзапроса является блокирующим фактором. Планировщик мог бы использовать индекс, если бы на месте подзапроса было простое условие с ИЛИ, сравнивающее колонку с набором констант – в этом случае его можно было бы преобразовать в конструкцию ANY. Однако с подзапросом такое преобразование невозможно, так как пришлось бы сканировать индекс целиком. Поэтому остановились на последовательном сканировании, так как это намного дешевле
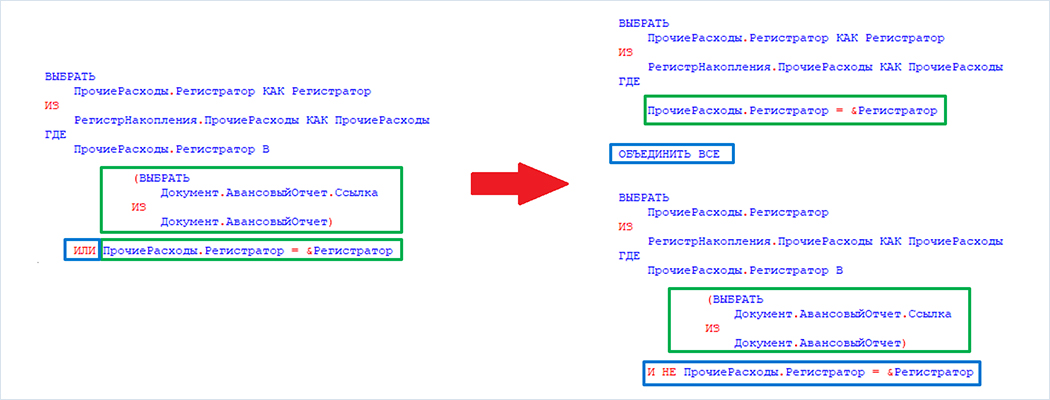 В таком случае запрос сможет использовать индекс и соответственно выполнится почти мгновенно. По условиям теста нельзя дорабатывать код 1С, поэтому пришлось обучить СУБД Tantor Postgres при планировании запроса автоматически переписывать текст запроса перед исполнением, если он подходит под указанный шаблон. Коллеги из «Тантор лабс» успешно справились с этой задачей, в результате чего запрос вместо 5 секунд выполнился за 1 мс, т.е. ускорение в 5 тысяч раз!
В таком случае запрос сможет использовать индекс и соответственно выполнится почти мгновенно. По условиям теста нельзя дорабатывать код 1С, поэтому пришлось обучить СУБД Tantor Postgres при планировании запроса автоматически переписывать текст запроса перед исполнением, если он подходит под указанный шаблон. Коллеги из «Тантор лабс» успешно справились с этой задачей, в результате чего запрос вместо 5 секунд выполнился за 1 мс, т.е. ускорение в 5 тысяч раз!
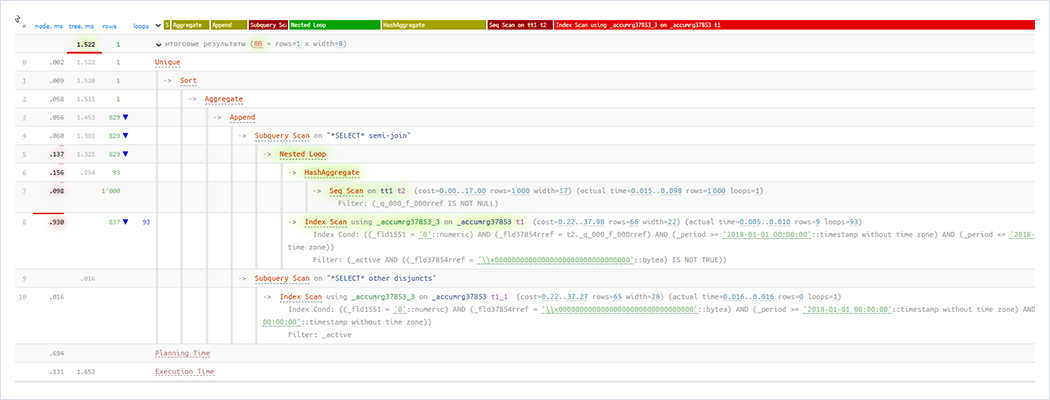 Таким образом, технология, реализованная в оптимизаторе запросов MS SQL Server и Oracle Database, теперь есть и в Tantor Postgres. Подробнее о настройках инстанса СУБД, оборудовании и итоговом результате APDEX расскажем в следующей, финальной части материала.
Таким образом, технология, реализованная в оптимизаторе запросов MS SQL Server и Oracle Database, теперь есть и в Tantor Postgres. Подробнее о настройках инстанса СУБД, оборудовании и итоговом результате APDEX расскажем в следующей, финальной части материала.
Будет интересно:
– Стенд для 30 000 АРМ: как мы автоматизировали подготовку виртуальных машин для нагрузочного теста
– Артефакты вместо хаоса: системный подход к сбору данных при нагрузке в 30 тысяч пользователей
– От логов до логики: сквозная наблюдаемость за 1С с помощью системы «Умный мониторинг»
Самое актуальное и интересное – у нас в telegram-канале!