
Инфраструктура исследуемой системы
- Технологическая платформа 1С:Предприятие 8, версия 8.3.22.2239
- Конфигурация: 1С:ERP. Управление холдингом (3.1.10.8)
- СУБД: PostgreSQL версия 14.5 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 8.3.1 20191121 (Red Hat 8.3.1-6), 64-bit
- Операционная система: РЕД ОС 7.3 МУРОМ
В статье подробно рассмотрен пример возникновения ошибки «Недостаточно памяти для получения результата запроса» и способ ее решения. Ошибка сигнализирует, что на уровне кластера 1С настроены механизмы «Счетчики потребления ресурсов» и «Ограничения потребления ресурсов» для используемой оперативной памяти. Рассмотрим работу этих механизмов. Настройка выполняется через консоль администрирования серверов 1С:Предприятия. Счетчик потребления ресурсов накапливает объем использованной оперативной памяти за серверный вызов (рис. 1).
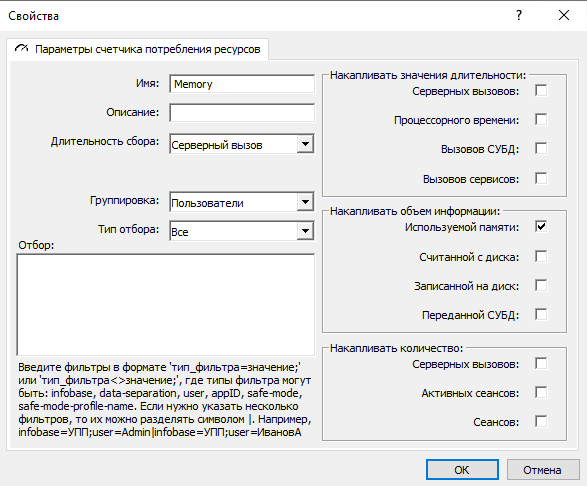
Рис. 1. Настройка счетчика потребления ресурсов для накопления используемой памяти
Ограничение потребления ресурсов прерывает серверный вызов при превышении предельного значения накопленного объема оперативной памяти (рис. 2).
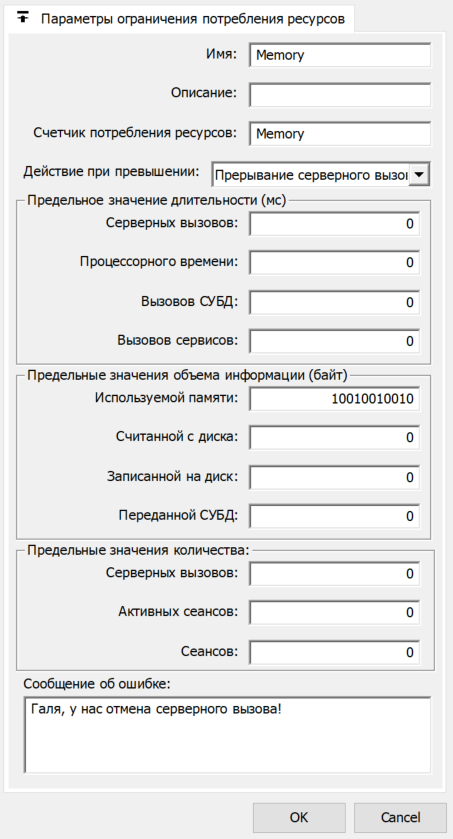
Рис. 2. Настройка ограничения потребления ресурсов для используемой памяти
«Счетчики потребления ресурсов» и «Ограничения потребления ресурсов» предназначены для того, чтобы обезопасить кластер серверов 1С от критической нагрузки, которая может привести к непоправимым или негативным последствиям. К тому же, эти механизмы являются удобным инструментом сбора информации о потреблении ресурсов кластером. Все накопленные показатели счетчиков хранятся в файле rescntsrv.lst в каталоге рабочих (центральных) серверов. Данные файла можно использовать во всевозможных системах мониторинга. Но в работе этого механизма есть важная неочевидная особенность. Работа счетчика использованной оперативной памяти с длительностью сбора «Серверный вызов» реализована следующим образом: значение счетчика проверяется после завершения выполнения одной строки прикладного кода и до перехода к следующей. Например, явное выполнение запроса или получение данных динамического списка — это, по сути, одна строка прикладного кода. Поэтому счетчик будет проверен перед строкой кода выполнения запроса и после его выполнения. И если система выявит, что в процессе выполнения строчки кода серверный вызов превысил установленное ограничение памяти, то серверный вызов будет прерван и выведено сообщение об ошибке.
Из этого следует, что в действительности серверный вызов все равно использует всю необходимую ему память, даже если она превышает ограничение во сколько угодно раз. Другими словами, использование счетчика потребления ресурсов оперативной памяти и установленное ограничение не решает проблему пикового повышенного использования памяти. Проблему необходимо решать на уровне программного кода. Одна из ситуаций, при которой возникла описанная ошибка, и путь ее решения представлен в данной статье.
Корень зла – неограниченная выборка данных!
Мы столкнулись с ошибкой «Недостаточно памяти для получения результата запроса» в одном из механизмов, который обеспечивает выполнение заданий обмена при интеграции с другими системами. Рассмотрим архитектуру этой подсистемы обмена. В упрощенном варианте она включает в себя план обмена «Регистрация изменений» и два регистра сведений «Задания» и «ЗаданияВРаботе».
План обмена «Регистрация изменений» хранит измененные объекты системы. В состав включаются объекты, участвующие в обмене с признаком авторегистрации. Регистр сведений «Задания» хранит список ссылок на объекты и дополнительные данные, которые необходимо отправить в другую систему.Измерения:
- Задание – УникальныйИдентификатор – обеспечивает уникальность каждого задания.
- Получатель – СправочникСсылка.Получатели – ссылка на систему-получателя.
- Приоритет – Число(3, 0) – приоритет задания. Чем выше приоритет, тем раньше необходимо обработать задание.
- Ссылка – ЛюбаяСсылка – ссылка на объект базы данных, который необходимо отправить.
- ХэшСумма – Число(10, 0) – хэшированное значение ссылки.
Регистр сведений «ЗаданияВРаботе» хранит список ссылок на объекты и дополнительные данные, которые в данный момент уже обрабатываются в фоновом задании для отправки в другую систему.
Измерения:- Задание – УникальныйИдентификатор – обеспечивает уникальность каждого задания.
- ФоновоеЗадание – УникальныйИдентификатор – идентификатор фонового задания, в котором обрабатывается задание.
Запрос = Новый Запрос;
Запрос.Текст =
"ВЫБРАТЬ
| Задания.Задание КАК Задание,
| Задания.ХэшСумма КАК ХэшСумма,
| Задания.Получатель КАК Получатель
|ИЗ
| РегистрСведений.Задания КАК Задания
| ЛЕВОЕ СОЕДИНЕНИЕ РегистрСведений.ЗаданияВРаботе КАК ЗаданияВРаботе
| ПО Задания.Задание = ЗаданияВРаботе.Задание
|ГДЕ
| ЗаданияВРаботе.Задание ЕСТЬ NULL
|
|УПОРЯДОЧИТЬ ПО
| Задания.Приоритет УБЫВ,
| Задания.Получатель,
| Задания.ХэшСумма";
Выборка = Запрос.Выполнить().Выбрать();
С определенной периодичностью запускается отдельное регламентное задание «Регистрация изменений», которое получает ссылки на объекты из таблицы регистрации изменений. Полученные ссылки на объекты записываются в регистр сведений «Задания».
Сортировка по убыванию приоритета используется, чтобы как можно раньше выполнить задания с наивысшим приоритетом. Сортировка по получателю и хэш-сумме используется, чтобы упорядочить задания для одного получателя по одинаковой ссылке на объект. Далее станет понятно, зачем это нужно.
При штатной работе в регистре сведений «Задания» хранится небольшое количество записей. Существует регламентное задание, которое запускается с достаточно коротким интервалом, выбирает задания для обработки и запускает фоновые задания для отправки объектов во внешние системы. При этом каждое фоновое задание записывает свой массив заданий в регистр сведений «Задания в работе», чтобы исключить повторное выполнение.
Но в процессе эксплуатации достаточно нагруженной системы в некоторый момент в регистре сведений «Задания» накопилось более 6 млн строк, что и привело к срабатыванию ограничения потребления ресурсов после выполнения запроса выше и возникновению ошибки:
Недостаточно памяти для получения результата запроса к базе данных{ОбщийМодуль.ОбменДанными.Модуль(1713)} : Выборка = Запрос.Выполнить().Выбрать();
{ОбщийМодуль.ОбменДанными.Модуль(149)} : ОбработатьЗадания(); по причине: Ошибка выполнения запроса по причине: Недостаточно памяти для получения результата запроса к базе данных
В технологическом журнале мы видим серверный вызов, который в пике потребляет 3.4 ГБ оперативной памяти:
06:47.983002-46258002,CALL,2,SessionID=3,Context=Форма.Вызов : ВнешняяОбработка.ЗапускОбработкиЗаданий.Форма.Форма.Модуль.ОбработатьЗаданияНаСервере,IName=IVResourceRemoteConnection,MName=send,Memory=24292,MemoryPeak=3407814052,InBytes=4776,OutBytes=0,CpuTime=6088974
Анализ работы текущего запроса заданий обмена
Перед тем как делать попытки уменьшить результат запроса и снизить потребляемую память, мы проверили, как текущий запрос заданий обмена выполняется на СУБД. Вот его план:
2024-04-26 14:06:43.626 MSK [1834367] LOG: duration: 41893.125 ms planning: 0.000 ms plan:Query Text: SELECT
T1._Fld130410,
T1._Fld130419,
T1._Fld130412RRef,
T1._Fld130413
FROM _InfoRg130409 T1
LEFT OUTER JOIN _InfoRg130420 T2
ON ((T1._Fld130410 = T2._Fld130421)) AND (T2._Fld3764 = CAST(0 AS NUMERIC))
WHERE ((T1._Fld3764 = CAST(0 AS NUMERIC))) AND (((T2._Fld130421) IS NULL))
ORDER BY (T1._Fld130413) DESC, (T1._Fld130412RRef), (T1._Fld130419)
Sort (cost=757646.35..763440.06 rows=5793711 width=79) (actual time=34082.739..38682.476 rows=6878020 loops=1)
Sort Key: t1._fld130413 DESC, t1._fld130412rref, t1._fld130419
Sort Method: external merge Disk: 504024kB
-> Hash Anti Join (cost=23972.74..178057.42 rows=5793711 width=79) (actual time=334.756..3787.414 rows=6878020 loops=1)
Hash Cond: (t1._fld130410 = t2._fld130421)
-> Seq Scan on _inforg130409 t1 (cost=0.00..88541.46 rows=6808851 width=47) (actual time=0.010..1577.195 rows=6878020 loops=1)
Filter: (_fld3764 = '0'::numeric)
-> Hash (cost=12425.92..12425.92 rows=1049711 width=17) (actual time=332.126..332.127 rows=1051299 loops=1)
Buckets: 2097152 Batches: 1 Memory Usage: 66691kB
-> Seq Scan on _inforg130420 t2 (cost=0.00..12425.92 rows=1049711 width=17) (actual time=0.009..146.052 rows=1051299 loops=1)
Filter: (_fld3764 = '0'::numeric)
По плану видно, что выполняется сканирование таблицы _inforg130420 (ЗаданияВРаботе) и в памяти строится hash-таблица. После чего сканируется таблица _inforg130409 (Задания), и выполняется проверка по hash-таблице, что Задание отсутствует в таблице ЗаданияВРаботе с помощью оператора соединения Hash Anti Join. Пока все хорошо. Далее, по полученному набору строк выполняется сортировка Sort. Свойства Sort Method: external merge Disk: 504024kB говорят о том, что для сортировки пришлось использовать временный файл на диске. Внешняя сортировка (external merge) занимает почти 90% всей длительности запроса. Надо что-то с этим делать.
Теперь мы ставим перед собой три задачи:- Уменьшить результат запроса, чтобы не попадать под ограничения потребления ресурсов по используемой памяти.
- Избавиться от внешней сортировки с использованием временного файла на диске.
- Сохранить длительность запроса в пределах 45 секунд. На таких огромных объемах данных длительные запросы — это неизбежно.
Поиск вариантов решения

Ограничиваем выборку данных из физических таблиц
Первый вариант решения был физически ограничить выборку запроса, применив конструкцию «ВЫБРАТЬ ПЕРВЫЕ N». Количество N определяем следующими служебными настройками:
- КоличествоПотоков – максимальное количество фоновых заданий, которые могут обрабатывать задания обмена;
- КоличествоОбъектовНаПотокОтправки – максимальное количество заданий обмена на один поток.
Получается, что КоличествоПотоков*КоличествоОбъектовНаПотокОтправки это и есть максимальное количество заданий обмена, которые будут обработаны за одну итерацию. Этим количеством мы можем ограничить выборку запроса.
Давайте сделаем это! Посмотрим на план запроса и технологический журнал. Для примера: ограничение выборки – 10000 записей:Запрос = Новый Запрос;
Запрос.Текст =
"ВЫБРАТЬ ПЕРВЫЕ 10000
| Задания.Задание КАК Задание,
| Задания.ХэшСумма КАК ХэшСумма,
| Задания.Получатель КАК Получатель
|ИЗ
| РегистрСведений.Задания КАК Задания
| ЛЕВОЕ СОЕДИНЕНИЕ РегистрСведений.ЗаданияВРаботе КАК ЗаданияВРаботе
| ПО Задания.Задание = ЗаданияВРаботе.Задание
|ГДЕ
| ЗаданияВРаботе.Задание ЕСТЬ NULL
|
|УПОРЯДОЧИТЬ ПО
| Задания.Приоритет УБЫВ,
| Задания.Получатель,
| Задания.ХэшСумма";
2024-04-26 14:24:35.018 MSK [1834367] LOG: duration: 4972.070 ms planning: 0.000 ms plan:
Limit (cost=1082864.19..1082874.19 rows=10000 width=79) (actual time=4965.753..4966.830 rows=10000 loops=1)
-> Sort (cost=1082864.19..1088657.90 rows=5793711 width=79) (actual time=4965.750..4966.325 rows=10000 loops=1)
Sort Key: t1._fld130413 DESC, t1._fld130412rref, t1._fld130419
Sort Method: top-N heapsort Memory: 3152kB
-> Hash Anti Join (cost=23972.74..178057.42 rows=5793711 width=79) (actual time=360.060..3352.304 rows=6878020 loops=1)
Hash Cond: (t1._fld130410 = t2._fld130421)
-> Seq Scan on _inforg130409 t1 (cost=0.00..88541.46 rows=6808851 width=47) (actual time=0.016..1325.084 rows=6878020 loops=1)
Filter: (_fld3764 = '0'::numeric)
-> Hash (cost=12425.92..12425.92 rows=1049711 width=17) (actual time=356.626..356.627 rows=1051299 loops=1)
Buckets: 2097152 Batches: 1 Memory Usage: 66691kB
-> Seq Scan on _inforg130420 t2 (cost=0.00..12425.92 rows=1049711 width=17) (actual time=0.015..156.545 rows=1051299 loops=1)
Filter: (_fld3764 = '0'::numeric)
В плане запроса видим, что вместо external merge теперь используется метод сортировки top-N heapsort, который выполняется полностью в памяти и не использует временные файлы.
24:35.170001-5122001,CALL,2,SessionID=3,Context=Форма.Вызов : ВнешняяОбработка.ЗапускОбработкиЗаданий.Форма.Форма.Модуль.ОбработатьЗаданияНаСервере,IName=IVResourceRemoteConnection,MName=send,Memory=23407,MemoryPeak=5360183,InBytes=4679,OutBytes=0,CpuTime=136193
По событию CALL технологического журнала пиковое потребление памяти чуть больше 5 МБ.

Рис. 3. Собаку-подозреваку что-то не устраивает
Порционная выборка из временной таблицы
Интуиция собаку-подозреваку не подвела. А что будет, если один объект взять и перезаписать больше 1 раза? А если 100 раз? А если 100 000 раз? Есть вероятность, что будет зарегистрировано множество заданий с одинаковой ссылкой на объект. И это сделано осознанно, чтобы не нагружать регламент обработки регистрации изменений дополнительными проверками, что задание по объекту уже существует. И в такой ситуации мы будем делать запрос к таблицам базы данных с выборкой «первых» много раз, получая и обрабатывая одинаковые задания. Будем сканировать многомилионные таблицы, соединять, сортировать и нагружать СУБД бесполезной работой.
Напомним, о чем мы писали выше. В регистре сведений «Задания» есть ресурс «ХэшСумма», вычисляемый из ссылки. Вот он и используется, чтобы разные задания обмена с одинаковой хэш-суммой (т.е. с одинаковой ссылкой на объект базы данных) не обрабатывать повторно (рис. 4).
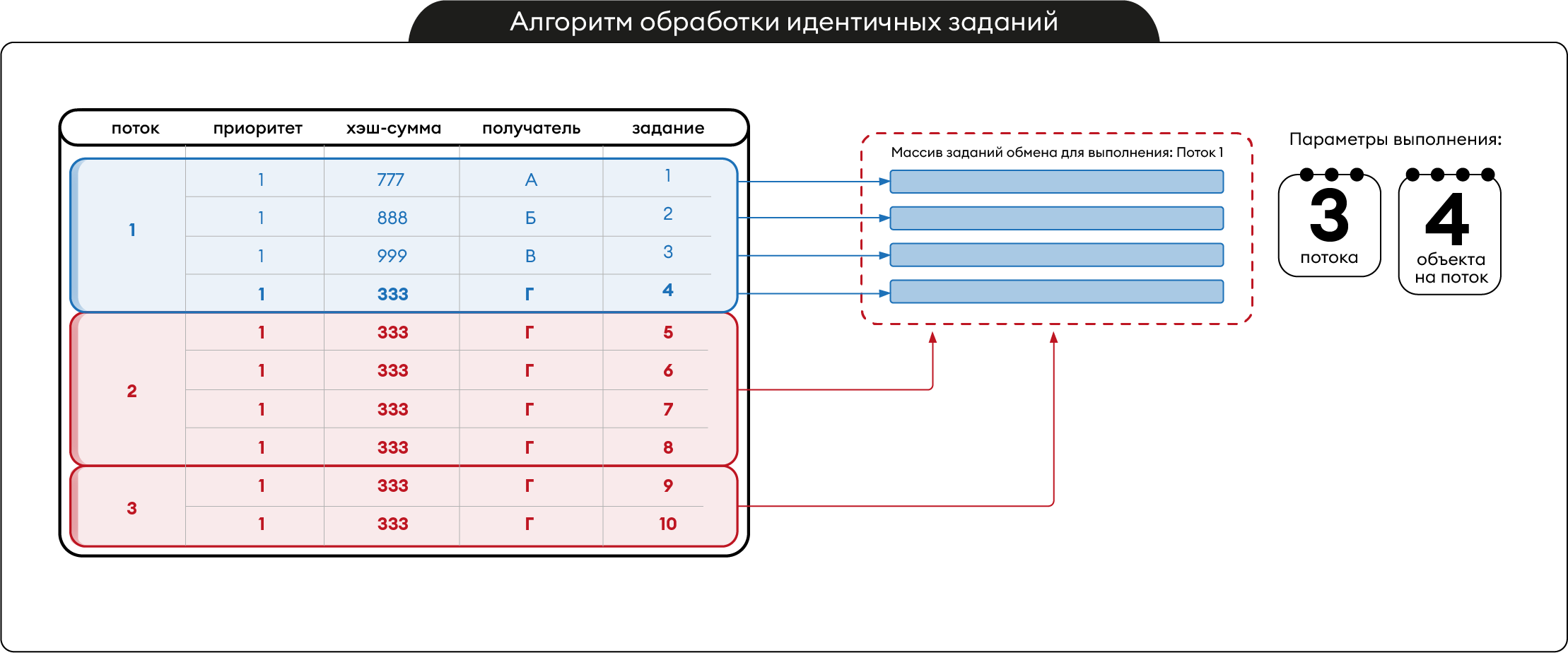
Рис. 4 – Алгоритм обработки идентичных заданий
По схеме на рисунке 4 слева представлена очередь заданий обмена из 10 заданий. Выполнение заданий запускается в 3 потока, в каждом потоке не более 4 заданий. Справа пунктиром представлен массив заданий обмена для потока 1. При этом видно, что все задания потоков 2 и 3 не отличаются от задания 4 из потока 1. Все они имеют одинаковую хэш-сумму «333» и получателя «Г». Следовательно, их тоже можно обработать в потоке 1 вместо того, чтобы запускать дополнительные потоки для обмена идентичными объектами. Так как мы не знаем сколько всего идентичных заданий в очереди, то вариант с ограничением выборки мы использовать не можем.
Для решения этой проблемы возвращаемся к нашим вариантам решения. Во-первых, попробуем перенести использование оперативной памяти с сервера приложений на СУБД. При корректной настройке сервера СУБД и правильной архитектуре приложения, сервер СУБД будет эффективно распоряжаться выделенной ему памятью, а при ее нехватке будет использовать ресурсы дисковой подсистемы. Во-вторых, организуем порционную выборку результатов запроса с СУБД. А для реализации этих идей будем использовать «Менеджер временных таблиц». Создадим временную таблицу со всеми заданиями в очереди обмена и исключим задания, которые уже обрабатываются. Эту временную таблицу будем хранить на сервере СУБД. После чего, уже ограниченными порциями будем получать записи на сервер приложений из этой временной таблицы, пока не обработаем все задания обмена, в том числе идентичные.
Инициализируем временную таблицу с заданиями обмена, которые не обрабатываются в данный момент:МенеджерВременныхТаблиц = Новый МенеджерВременныхТаблиц;
Запрос = Новый Запрос;
Запрос.МенеджерВременныхТаблиц = МенеджерВременныхТаблиц;
Запрос.Текст =
"ВЫБРАТЬ
| Задания.Приоритет КАК Приоритет,
| Задания.ХэшСумма КАК ХэшСумма,
| Задания.Получатель КАК Получатель,
| Задания.Задание КАК Задание
|ПОМЕСТИТЬ ВТ_Задания
|ИЗ
| РегистрСведений.кшдЗадания КАК Задания
| ЛЕВОЕ СОЕДИНЕНИЕ РегистрСведений.кшдЗаданияВРаботе КАК ЗаданияВРаботе
| ПО Задания.Задание = ЗаданияВРаботе.Задание
|ГДЕ
| ЗаданияВРаботе.Задание ЕСТЬ NULL
| И Задания.Получатель.ТочкаПодключения = &ТочкаПодключения
| И Задания.ДатаСоздания > ДАТАВРЕМЯ(1, 1, 1)
| И Задания.ДатаСоздания <= &ТекущаяДатаСеанса
|
|ИНДЕКСИРОВАТЬ ПО
| Приоритет,
| ХэшСумма,
| Получатель";
Запрос.Выполнить();
Результат запроса сохраняется во временную таблицу «ВТ_Задания», из которой мы будем дальше небольшими порциями получать задания обмена и обрабатывать их. Дополнительно мы добавили индексирование по полям Приоритет, ХэшСумма и Получатель, так как именно по этим полям мы будем делать сортировку и отбор порций.
Давайте посмотрим, что интересного в плане этого запроса:Insert on tt4 (cost=23998.72..204511.37 rows=0 width=0) (actual time=45414.874..45414.878 rows=0 loops=1)
-> Hash Join (cost=23998.72..204511.37 rows=6018052 width=47) (actual time=431.808..7376.048 rows=6878020 loops=1)
Hash Cond: (t1._fld130412rref = t3._idrref)
-> Hash Anti Join (cost=23972.74..198351.30 rows=5781983 width=47) (actual time=430.795..6146.063 rows=6878020 loops=1)
Hash Cond: (t1._fld130410 = t2._fld130421)
-> Seq Scan on _inforg130409 t1 (cost=0.00..108968.01 rows=6795068 width=47) (actual time=0.008..3203.117 rows=6878020 loops=1)
Filter: ((_fld130413 >= '0'::numeric) AND (_fld130418 > '0001-01-01 00:00:00'::timestamp without time zone) AND (_fld130418 <= '2024-04-16 15:34:17'::timestamp without time zone) AND (_fld3764 = '0'::numeric))
-> Hash (cost=12425.92..12425.92 rows=1049711 width=17) (actual time=419.482..419.484 rows=1051299 loops=1)
Buckets: 2097152 Batches: 1 Memory Usage: 66691kB
-> Seq Scan on _inforg130420 t2 (cost=0.00..12425.92 rows=1049711 width=17) (actual time=0.011..175.671 rows=1051299 loops=1)
Filter: (_fld3764 = '0'::numeric)
-> Hash (cost=15.00..15.00 rows=998 width=17) (actual time=1.002..1.004 rows=1000 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 56kB
-> Seq Scan on _reference130428 t3 (cost=0.00..15.00 rows=998 width=17) (actual time=0.098..0.676 rows=1000 loops=1)
Filter: ((_fld3764 = '0'::numeric) AND (_fld130432rref = '\\x9411005056a1ff1c11eef597760ef90e'::bytea))
Как мы видим, длительность запроса особо не поменялась (было 42 секунды, теперь – 45 секунд). Ранее самым длительным оператором была сортировка, сейчас это создание индексированной временной таблицы. Сканирование таблиц _inforg130409 (Задания) и _inforg130420 (Задания в работе) осталось неизменным, но мы перестали использовать диск за счет избавления от сортировки 6 млн строк.
Как видно по коду, выполняется только метод Запрос.Выполнить(). Таким образом, весь результат запроса остается на СУБД и не передается на сервер приложений. На сервере приложений не выделяется память для хранения всего результата запроса. Теперь можно сколько угодно раз порционно получать записи этой временной таблицы и передавать их на сервер приложений. Для этого мы используем несколько запросов с различными отборами и конструкцией «ВЫБРАТЬ ПЕРВЫЕ N». Ограничение первых записей равно N, где N – Количество потоков * КоличествоОбъектовНаПоток.
Давайте посмотрим на некоторые запросы порций заданий обмена и проанализируем их планы. Это запрос самой первой порции, когда мы не задаем никаких отборов, а лишь ограничиваем выборку:
Запрос = Новый Запрос;Запрос.МенеджерВременныхТаблиц = МенеджерВременныхТаблиц;
Запрос.Текст =
"ВЫБРАТЬ ПЕРВЫЕ 1000
| Задания.Задание КАК Задание,
| Задания.ХэшСумма КАК ХэшСумма,
| Задания.Получатель КАК Получатель,
| Задания.Приоритет КАК Приоритет
|ИЗ
| ВТ_Задания КАК Задания
|
|УПОРЯДОЧИТЬ ПО
| Приоритет УБЫВ,
| ХэшСумма УБЫВ,
| Получатель УБЫВ,
| Задание УБЫВ";
Выборка = Запрос.Выполнить.Выбрать();
2024-04-16 15:35:05.389 MSK [1031767] LOG: duration: 8.237 ms planning: 0.000 ms plan:
Limit (cost=0.99..96.47 rows=1000 width=47) (actual time=0.307..7.699 rows=1000 loops=1)
-> Incremental Sort (cost=0.99..656710.99 rows=6878020 width=47) (actual time=0.306..7.640 rows=1000 loops=1)
Sort Key: _q_000_f_003 DESC, _q_000_f_001 DESC, _q_000_f_002rref DESC, _q_000_f_000_00 DESC
Presorted Key: _q_000_f_003, _q_000_f_001, _q_000_f_002rref
Full-sort Groups: 32 Sort Method: quicksort Average Memory: 27kB Peak Memory: 27kB
-> Index Scan Backward using tmpind_0 on tt4 t1 (cost=0.17..242256.81 rows=6878020 width=47) (actual time=0.041..7.198 rows=1001 loops=1)
Выполняется обратный обход созданного индекса (Index Scan Backward using tmpind_0 on tt4) временной таблицы «ВТ_Задания». Мы знаем, что строки в индексе отсортированы, поэтому оптимизатору запросов нет необходимости выполнять отдельную сортировку по полям индекса «Приоритет, ХэшСумма, Получатель». Обратите внимание, что теперь сортировка выполняется строго в одном направлении «УБЫВ» по всем полям. Именно это и позволяет не выполнять дополнительную сортировку по полям, а использовать преимущество упорядоченного хранения данных в индексе. Далее выполняется лишь мгновенная инкрементальная сортировка (Incremental Sort) по полю «Задание».
Мы намеренно не стали добавлять в индекс временной таблицы это поле. Тесты показали, что выполнить инкрементальную сортировку гораздо быстрее, чем строить индекс временной таблицы с учетом этого поля. Итого, имеем эффективный обход индекса, мгновенную инкрементальную сортировку в памяти и ограничение (Limit). Limit 1000 позволил планировщику не читать весь индекс временной таблицы, а ограничиться чтением первых 1001 строк (rows=1001) и на этом остановиться. Длительность выполнения запроса – 8.237 мс.
Еще один запрос порции из «ВТ_Задания», который выбирает все задания обмена с таким же приоритетом, как был в предыдущей порции, но с отличающейся хэш-суммой:
Запрос = Новый Запрос;Запрос.МенеджерВременныхТаблиц = МенеджерВременныхТаблиц;
Запрос.Текст =
"ВЫБРАТЬ ПЕРВЫЕ 1000
| кшдЗадания.Задание КАК Задание,
| кшдЗадания.ХэшСумма КАК ХэшСумма,
| кшдЗадания.Получатель КАК Получатель,
| кшдЗадания.Приоритет КАК Приоритет
|ИЗ
| ВТ_Задания КАК кшдЗадания
|ГДЕ
| кшдЗадания.Приоритет = &ПредыдущийПриоритет
| И кшдЗадания.ХэшСумма < &ПредыдущийХэш
|УПОРЯДОЧИТЬ ПО
| Приоритет УБЫВ,
| ХэшСумма УБЫВ,
| Получатель УБЫВ,
| Задание УБЫВ";
Выборка = Запрос.Выполнить.Выбрать();
2024-04-16 15:35:05.430 MSK [1031767] LOG: duration: 11.676 ms planning: 0.000 ms plan:
Limit (cost=0.42..171.32 rows=1000 width=47) (actual time=0.620..10.852 rows=1000 loops=1)
-> Incremental Sort (cost=0.42..137557.95 rows=804890 width=47) (actual time=0.619..10.758 rows=1000 loops=1)
Sort Key: _q_000_f_001 DESC, _q_000_f_002rref DESC, _q_000_f_000_00 DESC
Presorted Key: _q_000_f_001, _q_000_f_002rref
Full-sort Groups: 32 Sort Method: quicksort Average Memory: 27kB Peak Memory: 27kB
-> Index Scan Backward using tmpind_0 on tt4 t1 (cost=0.17..94890.18 rows=804890 width=47) (actual time=0.075..10.203 rows=1001 loops=1)
Index Cond: ((_q_000_f_003 = '5'::numeric) AND (_q_000_f_001 < '4289670381'::numeric))
И опять мы видим эффективный обратный обход индекса и мгновенную инкрементальную сортировку. План запроса и его анализ не отличается от того, что мы описывали выше.
Теперь давайте посмотрим, сколько оперативной памяти потребляет серверный вызов, когда мы храним временную таблицу всех заданий обмена на СУБД и порционно получаем из нее результаты на сервер приложений:
До:06:47.983002-46258002,CALL,2,SessionID=3,Context=Форма.Вызов : ВнешняяОбработка.ЗапускОбработкиЗаданий.Форма.Форма.Модуль.ОбработатьЗаданияНаСервере,IName=IVResourceRemoteConnection,MName=send,Memory=24292,MemoryPeak=3407814052,InBytes=4776,OutBytes=0,CpuTime=6088974
После:
35:06.932001-49093001,CALL,2,SessionID=6, Context=Форма.Вызов : ВнешняяОбработка.ЗапускОбработкиЗаданий.Форма.Форма.Модуль.ОбработатьЗаданияНаСервере,IName=IVResourceRemoteConnection,MName=send,Memory=358295,MemoryPeak=20483415,InBytes=5967,OutBytes=253412,CpuTime=1052558
Длительность вызова практически не изменилась. До оптимизации она составляла 46 секунд, после оптимизации – 49 секунд. А вот пиковая потребляемая память снизилась в 166 раз! До оптимизации использовалось 3.4 ГБ памяти, после оптимизации – 20 МБ.
Заключение
Давайте подведем краткие итоги всего, что было ранее написано. Перед нами стояла задача снизить потребляемую оперативную память в механизме обработки заданий обмена. Это позволило бы устранить ситуацию, при которой срабатывало ограничение потребления ресурсов памяти во время получения результатов запроса с неограниченной выборкой данных. При этом, из-за некоторых функциональных особенностей мы не могли принудительно ограничить выборку из физических таблиц, то есть использовать конструкцию «ВЫБРАТЬ ПЕРВЫЕ N». Нам нужно было получать таблицы полностью. Далее обходить результат небольшими порциями и прекращать обход при достижении определённых условий. Для этого мы решили, что полный результат запроса с неограниченной выборкой мы будем хранить не на сервере приложений, а на сервере СУБД. И уже на сервер приложений будем возвращать данные небольшими порциями.
Кроме того, мы провели максимально детальный анализ и оптимизацию всех запросов на выборку заданий обмена. Убедились, что в планах запросов используются самые эффективные операторы поиска, соединения и сортировки.
Неэффективное использование оперативной памяти может привести к «безобидным» последствиям, когда на сервере приложений ее достаточно и повышенное потребление пройдет бесследно для пользователей и системы. А может привести к катастрофическим, когда сервер приложений аварийно завершит свою работу. Поэтому очень важно придерживаться нескольких правил:
- Не менять без необходимости стандартные значения параметров рабочего сервера, связанные с контролем потребляемого объема памяти.
- Не устанавливать дополнительное тяжелое программное обеспечение, о котором 1С ничего не знает и которое вы не можете ограничить в потреблении памяти, на сервер приложений 1С, чтобы система мониторинга кластера работала корректно.
- Для систем уровня КОРП дополнительно настраивать «Счетчики потребления ресурсов» и «Ограничения потребления ресурсов», которые помогут быстро обнаружить и локализовать проблему.
- При разработке приложения всегда помнить, что оперативная память сервера ограничена, и следует избегать работы с большими данными в памяти.
Автор: Максим Кулбараков,
ведущий эксперт по технологическим вопросам
Самое актуальное и интересное - у нас в telegram-канале!